 [OC] (Some of) the biggest differences between Brits and Americans
[OC] (Some of) the biggest differences between Brits and AmericansSubmitted by spicer2 t3_11uk6ia in dataisbeautiful
spicer2
 [OC] The most common song titles in music
[OC] The most common song titles in musicSubmitted by spicer2 t3_11r437e in dataisbeautiful
 [OC] The most dominant athletics world records
[OC] The most dominant athletics world recordsSubmitted by spicer2 t3_11jvqtb in dataisbeautiful
 [OC] Logan Paul has great timing: energy drinks are now as popular with Gen Z as beer
[OC] Logan Paul has great timing: energy drinks are now as popular with Gen Z as beerSubmitted by spicer2 t3_11e45yf in dataisbeautiful
 [OC] Song titles are getting LOUDER but also quieter: the rise of ALL CAPS and all lower case pop music
[OC] Song titles are getting LOUDER but also quieter: the rise of ALL CAPS and all lower case pop music [OC] Men have more fun dreams: the most distinctive themes dreamed by each gender
[OC] Men have more fun dreams: the most distinctive themes dreamed by each genderSubmitted by spicer2 t3_1170sdz in dataisbeautiful
 [OC] Rates of anxiety and depression have spiked since the start of the pandemic
[OC] Rates of anxiety and depression have spiked since the start of the pandemicSubmitted by spicer2 t3_11181t2 in dataisbeautiful
 [OC] No-one wants me to stay safe anymore: the rise and fall of the pandemic email signoff
[OC] No-one wants me to stay safe anymore: the rise and fall of the pandemic email signoffSubmitted by spicer2 t3_10v4hn5 in dataisbeautiful
 [OC] Herd you liek Mudkips: the most (and least) memorable Pokemon
[OC] Herd you liek Mudkips: the most (and least) memorable PokemonSubmitted by spicer2 t3_10nftja in dataisbeautiful
 [OC] Hours of the day that appear most frequently in song titles
[OC] Hours of the day that appear most frequently in song titlesSubmitted by spicer2 t3_10dswee in dataisbeautiful
 [OC] The most quoted verses in each book of the Bible
[OC] The most quoted verses in each book of the BibleSubmitted by spicer2 t3_106mzab in dataisbeautiful
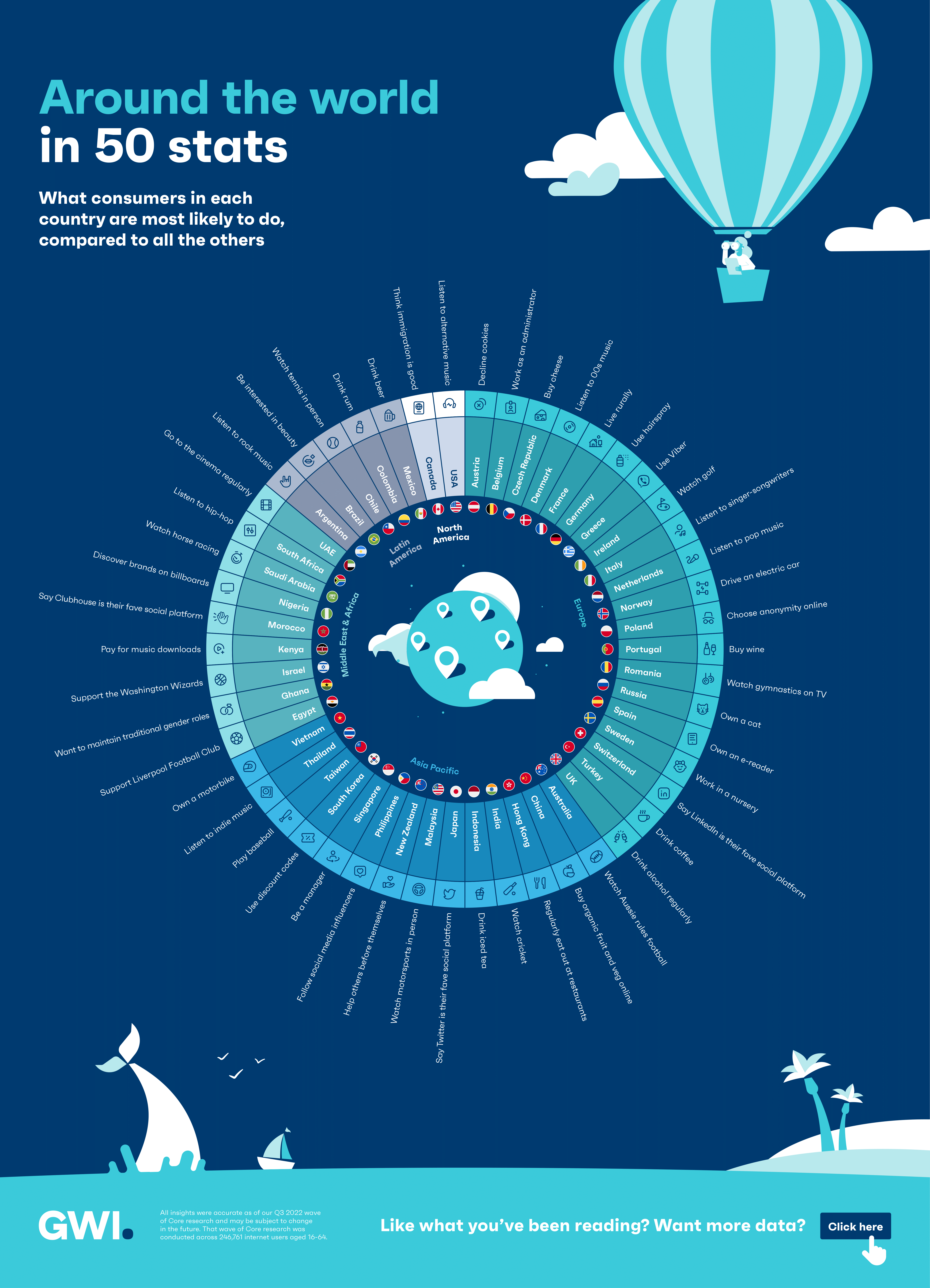 [OC] Mexican beer and New Zealand’s selflessness: the most distinctive traits and behaviors of 50 countries around the world
[OC] Mexican beer and New Zealand’s selflessness: the most distinctive traits and behaviors of 50 countries around the world
spicer2 OP t1_jc6fzop wrote
Reply to [OC] The most common song titles in music by spicer2
Tools: Excel
Source: MusicBrainz (online music encyclopedia)
Methodology/FAQs: I've seen a few other people attempt to figure this out but I've never been completely satisfied with their methodology. Music YouTuber David Bennett Piano has a video where he used Wikipedia disambiguation pages to arrive at a final list which is clever, but not robust enough for my tastes.
I had to do some careful filtering on the data to make it useful, so to be clear on what you’re seeing: this is the number of *original compositions* with that title. This means cover versions are excluded – if you don’t do that, the list is just full of Christmas songs that have been recorded many times over. I also filtered it so it is only *songs* – this means things like musicals, soundtracks, and classical albums are excluded (otherwise you get a load of “Preludes”). This is also why the figures are lower than some other sources you might have seen for this kind of data.
Some other interesting tidbits:
-”I Love You” is 28th in the all-time list;
-The most common animal is “Butterfly” (55th);
-The most common color is “Blue” (61st);
-”Untitled” (as in, an actual title called “Untitled”) is 63rd;
-The most commonly used place name is "California" (75th);
-If you exclude “Grace”, the most common name is “Maria”. And if you exclude that, it’s “Caroline” (unsweetened).